|
Knowing what is happening under the hood of different types of algorithms is important. I was once asked in an interview to explain a project that I had worked on and I decided to talk about my favorite portfolio project that tested a variety of algorithms to predict the likelihood of an MLB baseball player receiving the Gold Glove Award at the end of the season based on their season defensive metrics. I was happy with the way I explained my project and how in the end, an AdaBoost classifier was the best algorithm for my model. My interviewer nodded, expressed his intrigue and then, asked me to break down what the AdaBoost model does and how it works under the hood.......
Que stumbling, rambling, vocalized proof that I don't actually know the real details but I know it's better and uses like....more trees???....or something like that??? Before an interview you prepare and study and practice and talk to yourself in the mirror and there's always a question that will come up that you are unprepared for. So, I took notes on what I missed, hit the books to study up on the question I got wrong and here is how I would explain it if I could go back in time. I hope this helps you prepare for better explaining the details behind various ML algorithms. First, let's cover the difference between strong learners and weak learners. A weak learner is any model that does, just, good. It is predictive and it does better than random chance, slightly better that is. It can really be any kind of model or algorithm, but for the purpose of this exercise, think of it as a simple, shallow, non-tuned, vanilla decision tree. Now, think of strong learners as more than just that one simple, shallow, non-tuned, vanilla decision tree. Think of a strong learner as a random forest. Whereas before, we only had 1 tree, now we have multiple trees, each learning from a random subset of your overall training data (a technique called bagging) and each tree trains itself enough to make the forest model a strong learner, predicting better than random guessing. Weak Learners: Simple models that do only slightly better than random chance. Strong Learners: Models with the goal of doing as well as possible on the classification or regression task they are given. Examples include ensembles like random forests and boosters, A boosting algorithm is similar to that of a random forest because it ensembles trees together. First, a boosting algorithm will train a simple weak learner. It then evaluates which examples the weak learner got wrong and builds another weak learner that focuses on only the areas that the original got wrong. It continues doing this, building an overall strong learning model by iterating and building a more predictive and better trained or 'boosted' tree. Think of it as the algorithm looking back to see what went wrong, and giving the decision tree a little boost in the right direction. In the image below, you can see that the plus and minus signs change at every iteration. The first iteration is a very weak learner and at every iteration, the learner gets stronger. As the pluses and minuses are guessed right and wrong, their weights decrease and increase respectively. In the end, boosting has created a strong, predictive learner by starting with the a weak learner. It's a good old fashion strength boost! 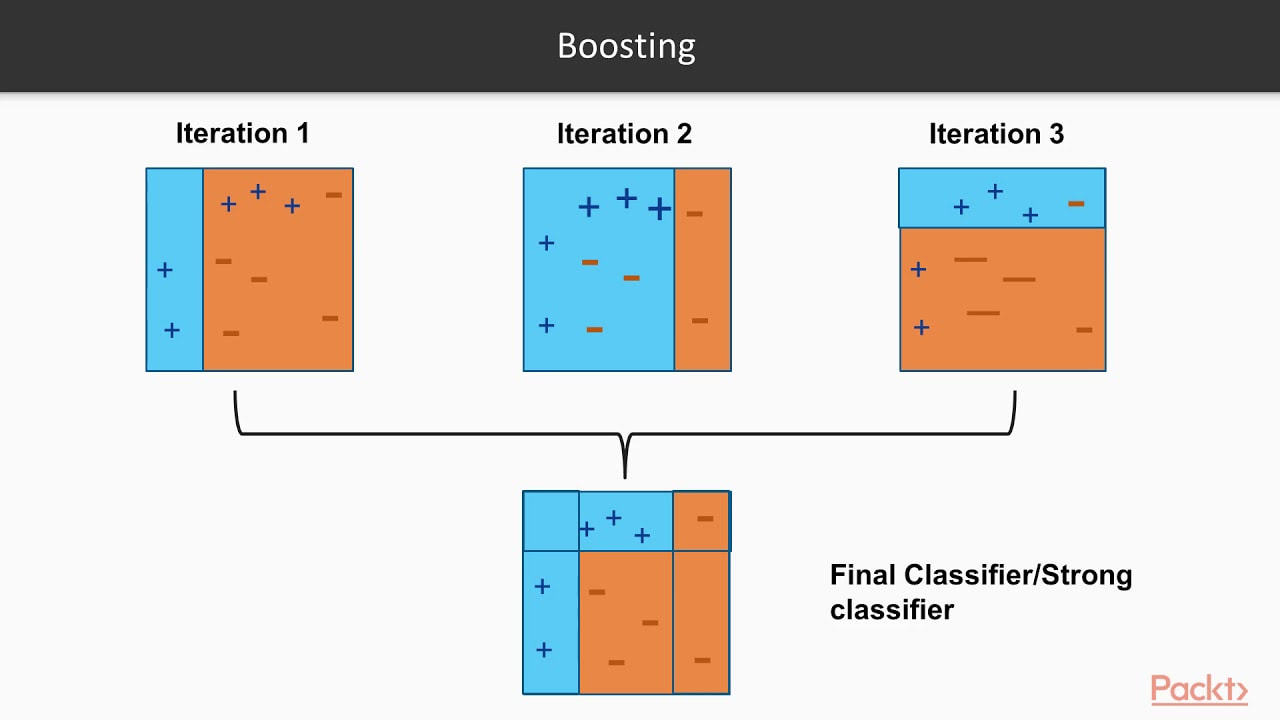
Image taken from a great video by Packt> : https://www.youtube.com/watch?v=BoGNyWW9-mE
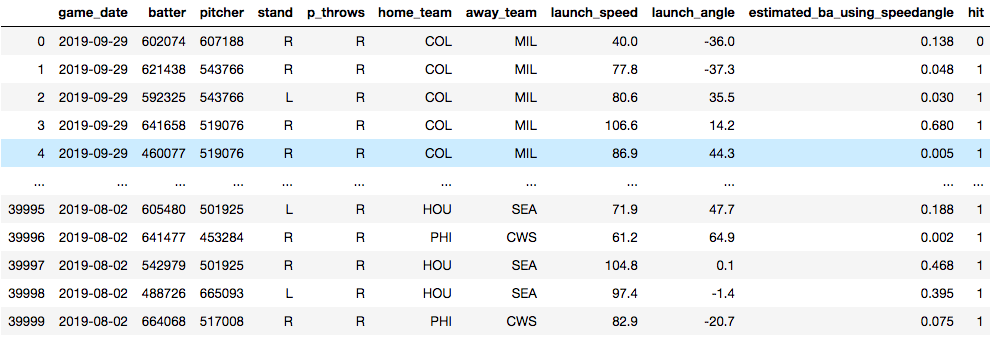
Now, time for an example. Below, you see a data set that I am using to train a model to predict whether or not a baseball player will get a hit. The model is trained on things like who the pitcher was, who the hitter was, how hard the ball was hit and at what angle the ball was struck. Essentially, I'm training a model in hopes that I'll later be able to predict what hitters will get hits against what pitchers. The data will need some tweaking to be sure, but for now, it's useful for this demonstration.
Vanilla Decision Tree
Training Accuracy: 100.0% Test Accuracy: 73.9% ------------------------------------------------------ Random Forest: Training Accuracy: 99.02% Test Accuracy: 79.11% ------------------------------------------------------ Adaboost: Training Accuracy: 80.13% Test Accuracy: 80.24% ------------------------------------------------------ In the end, we have some serious overfitting happening in the training of both the vanilla decision tree and the random forest, but we can see that the Adaptive Boosting model shows the best accuracy. An important point to note is the operational cost of boosting models. They take a lot of time. Training tree and tree and slowly making it just a little bit better each time will make for a long training time. Certainly there is a lot to dive into when it comes to evaluating a model, but I'll end it here. Try it out with your own datasets and see what results you can get.
0 Comments
Leave a Reply. |
 RSS Feed
RSS Feed
