Predicting Gold Glove Award Winners using Machine Learning
Can machine learning algorithms predict which MLB players will receive Gold Glove Awards at the end of a season? The Gold Glove Award is given to the best defensive player at each position in each league at the end of every season. Advanced metrics and traditional statistics were combined into a data table showing MLB players and their end of season stats from 2002 - 2018. The target column shows a 1 for a player who received an award and a 0 for players who did not. The data used for this classification model can be downloaded in .csv format here:

Choosing the Right Model
Now, I have my data all ready to go. I have my target column. I have also taken the steps as follows:
- drop.na() to remove any null values pertaining to catchers. The final data frame will only be learning on 7 fielding players (1B, 2B, SS, 3B, LF, CF, RF) - one hot encode to get dummies and create categorical values for position columns - separate out features and scale the data - Train/Test split at .75/.25 So, what's next? I've done a lot of work and I haven't begun any learning with machines yet. Where do I start? First off, it's important to know which algorithm to use. With so many models to choose from, you could spend all day running models and checking to see how they perform. But here I'll break down two. We will compare a baseline (or, Vanilla) Decision Tree model with a Random Forest model to see how each one performs and which will be a better model for our data. Decision Trees
Imagine that you are walking through the woods with a tree identification guide. All the trees in the woods are of the same species. They look the same, they smell the same, they have the same leaves. Let's say you are trying to identify this type of tree. You open your book to the first page and look at the tree in the picture. You start with the leaves. The picture in the book has 5 pointed, star-like, looking leaves. The tree you are standing under has round smooth leaves. The leaves just don't match up. What would you do? Hopefully, you wouldn't immediately give up because tree identification can be tough, but you instead turn the page to see if the next tree in the book can narrow your guesses down.
This, in effect, is what a decision tree does. Try not to get too confused about the tree metaphor being used to explain a decision tree. The point is, you start somewhere and answer yes/no, if/else questions to narrow down your classification. The decision tree algorithm does just the same thing. Using the tree identification metaphor, the leaves, the bark, the height, the smell, these are all features that you are using to predict a target, or the tree species. The algorithm does this with the features in your data set and passes them through the tree until a stop criteria is met. 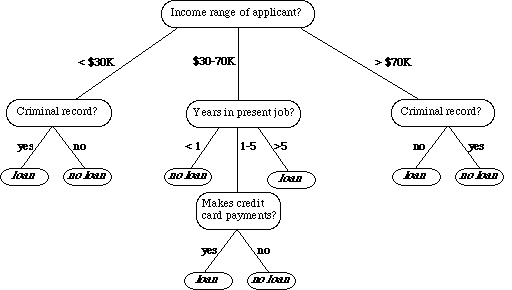
An example of a decision tree., Ref: TowardsDataScience.com
Here is the code used to run a baseline Decision Tree on my data:
A Random Forest
In the case of this project, we are working on a classification task. A Random Forest is essentially a collection of many Decision Trees and is an ensemble of a Decision Tree. Imagine now you're hiking through the woods and you stop to observe the trees in a new forest. You may see some spruce, some pines, some holly, some oak and maybe even some aspen (Aaahhh...) Though it sounds more like you would be walking through an arboretum than a wild forest, in technical terms, you are in a Random Forest Algorithm. But don't worry, there are no wild beasts to be afraid of.
In our metaphor you are now walking in a more diverse forest with many different species of trees. So, a Random Forest uses a varied approach to making decisions. It does this in two ways, bagging and subspace sampling. Bagging Just like different trees (pine, spruce, oak) will contribute differences to the forest, the bagging technique encourages differences when interpreting the data. Simply put, each tree is given a 'bag' of data. But, each bag is separated into it's own little training/testing subset. So, just like each tree in the real-world forest has different qualities, each tree in the algorithm has different samples of data from which to make decisions. Subspace Sampling In the same way bagging takes small portions of data to feed to each tree at random, subspace sampling feeds each tree a subset of features to train the tree. Think of this as each species of tree in the forest receiving a different amount of nutrients, sunlight and water. The algorithm is feeding different features to each tree in the model. The model then combines all trees in the forest to create a diverse and differentiated classification model.
Here is the code used to run a Random Forest on my data:
Evaluating and Comparing the Models
So, there you have it. Our data was split, each model was trained and used to predict which players should be receiving awards. Let's take a look at how we did.
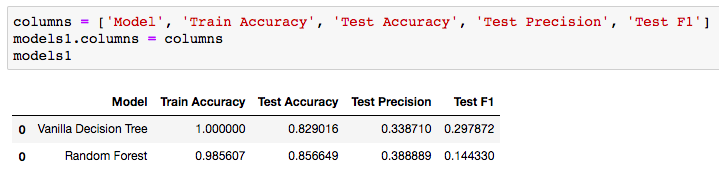
Analyzing and Comparing the Metrics
Accuracy
The 100% training accuracy can be ignored for the Vanilla Decision Tree. This is a result of training the model on the same data that it is being tested on. A great discussion of why this happens can be found here. The fact that the Vanilla model has 100% training accuracy and the Random Forest has a 98.5% training accuracy proves that the bagging and subspace sampling techniques are being used in the forest algorithm. The real column to look at above would be the Test Accuracy. We can see that using a Random Forest adds nearly .03 accuracy to our testing set. This shows how the randomness and diversity in decision making of the Random Forest can boost your testing accuracy. Precision In my Gold Glove Award classification model, I wanted to improve on precision as best I could. In this case, let's say my model predicted 100 players who should receive the gold glove and only 38 of those were accurate. Thus, giving us the .388889. Certainly we would hope that hyper-parameter tuning on the Random Forest would improve our precision, but it is better then the decision tree. Hopefully, this gives you a nice understanding of the difference between these two models and how an ensemble method, such as a Random Forest, can contribute to more predictive models. The full repo for the Gold Glove Award Winner classification project can be found here: https://github.com/lucaskelly49/dsc-3-final-project-online-ds-sp-000/blob/master/Student_Final.ipynb
0 Comments
|
|||
 RSS Feed
RSS Feed
