|
Analyzing baseball data is an excellent way to practice all skills required of an everyday data scientist. Every motion and movement of the ball and players on the field is coupled with some kind of data point. Baseball data will undoubtedly need to be cleaned and scrubbed no matter what source you obtain it from. The exploratory element can be a lot of fun for the creative and baseball knowledgeable analyst. But, the modern game of baseball has advanced so significantly because of the predictive power of baseball data and what can be hidden inside. In the end, whatever data analysis is done to a set of baseball data is directly transferable to any other type of data. The tools and skills are the same. Below, I'll showcase just that by showing how to merge data frames using pandas.  Aaron Judge collected all kinds of data points with just one swing in the home run derby. The Baltimore Orioles and the New York Yankees played a regular season game on August 14th, 2019. Let's start with a data frame that shows all the players in the line-up and on the field that day, their MLBID and their team. Note that depending on where you obtain your data, the player codes may be different. Here, I obtained this data from an MLB pitchF/X source, so the MLBID code is one that is unique to each player and significant to only MLB data. 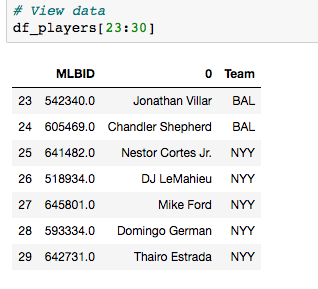 Now, let's say that we were given the data frame below. We were told that this is player value data from 8 players in the lineup that day. We are missing the player's names, but we have a "playerid" column. However, the playerID is different from the MLBID listed in the data frame above. Let's just say we were told that this data came from Fangraphs.com. We could have figured that out on our own with a little digging but I'll keep this simple. We need to merge these two data frames but we do not have a common column to do so. What can we do? 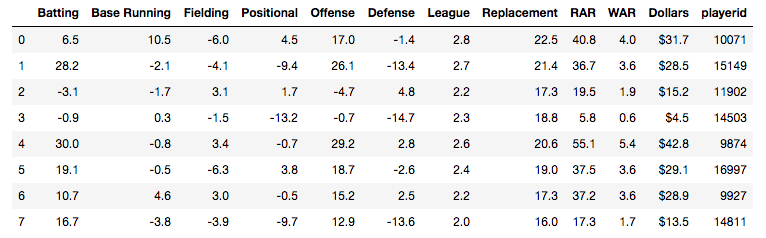 Luckily, there is a great resource on a website called Smart Fantasy Baseball that offers a data frame with a wide range of playerID codes for conversion purposes. We can download this information and use it to our advantage. Here, I download the .csv, import the data into a df and subset to only contain the MLBID and FangraphID codes that I need. In addition, I change the column names so that I can easily merge later.  Now, I just need to convert the columns to strings in both datasets, utilize pd.merge and boom!, I've merged the playerID df and the Fangraphs df using the Fangraphs player ID column that was common to both df's. 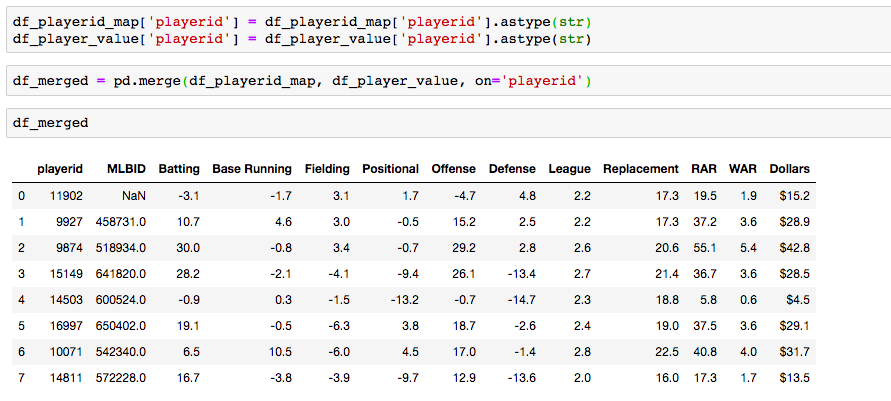 Remember when I said there will always be cleaning and scrubbing to do? Well you may notice above that playerID 11902 is missing and MLBID. This is a result of the playerID map that we downloaded being slightly out of date. A quick Google search and background knowledge of the Baltimore Orioles will tell us that Fangraphs ID code 11902 represents Hanser Alberto. We can then look up his MLBID and input that value manually. 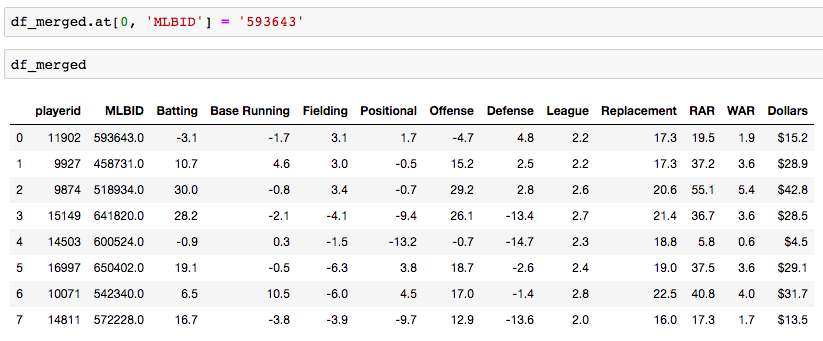 Now, our last step. We have merged MLBID's with FangraphID's in the step above. We still have our data frame that contains player names, their team and their MLBID. Our last step is to merge this original data with our newly merged df. 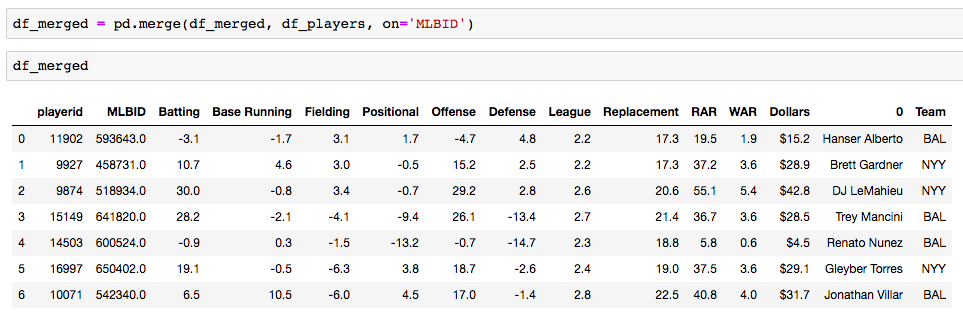 There you have it! We have successfully converted playerID codes and merged data frames with the help of Smart Fantasy Baseball's playerID map and Pandas! Perhaps next we can compare player value from the Orioles with player value from the Yank....no, no, let's not. I hope this helps you with any kind of merge or inspires you to start analyzing baseball data. Further Reading:
Link to my notebook. Pandas merge documentation. Interested in doing baseball research? Start with a few of these great sites! Fangraphs.com's leaderboards. Smart Fantasy Baseball. MLB PitchF/X Data.
0 Comments
|
 RSS Feed
RSS Feed
